This project involved building a Q-learning agent that learns the most optimal switching mechanism at a traffic intersection to reduce the delay of cars waiting at the intersection.
At each tick, the Q-learning agent assesses the current environment state in order to choose an action that will maximise the reward. This reward-seeking behaviour takes into account future rewards via a supplied Γ (Gamma) parameter.
Reinforcement learning
Reinforcement learning is an extension of temporal difference learning (TD learning) where an agent learns from making decisions and observing the reward given. The agent to learn the state values and resulting rewards to guide the agent towards optimal decisions.
Q-learning is one method of implementing TD-learning. It involves selecting an action based on a policy, observing the next state and the reward in order to update an internally constructed payoff matrix, the “Q-table.”
Finally, the agent selects its policy such that there is an element of exploration via the ε (Epsilon) parameter in order to explore all states given sufficient time steps.
Files
q_learning.pyis the re-usable q-learning agent that maintains a mapping of state -> rewards for taking each action (i.e. reward for keeping lights the same and reward for switching lights)traffic.pyis the actual pygame simulation file that renders out the individual lights, cars, lanes etc. It also instantiates a QLearningAgent and calls the agent to decide what action to take next
Results
Q-learning (Orange) vs switching automatically every 3 ticks (Blue)
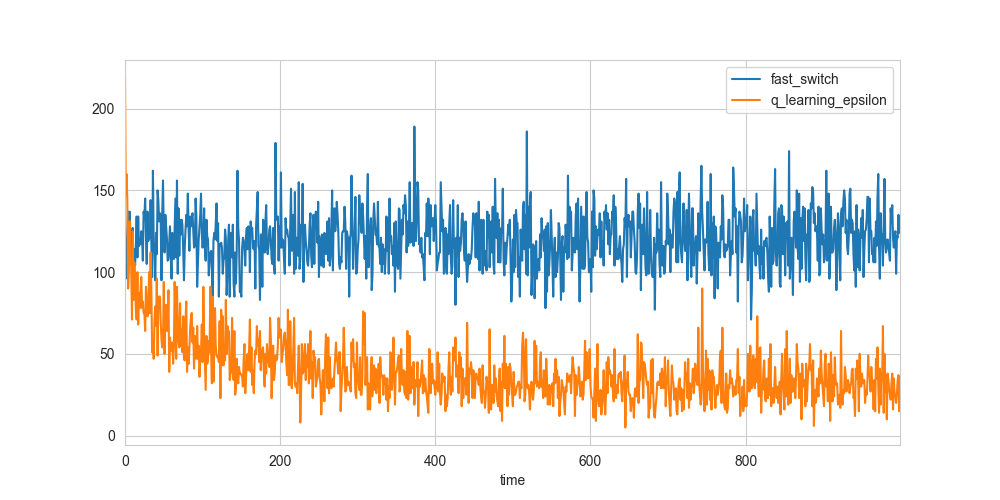
X-axis are clock ticks (in 1000s) and the y-axis is the penalty score. The penalty score is given by the sum total of the number of cars waiting at both intersections every 1000 clock ticks.
As you can see, Q-learning performs better as the simulation runs.