
Git is a version control system that helps track progress of a repository over time. One of the essential parts of using git is learning the commit system.
However, when someone learns git and the commit system for the first time they are told to ✨memorize the magic commands✨, without knowing what’s happening under the hood. So the goal of this post is to dig deeper and understand:
This post will not teach you how to use git. It will be exploring the internals of git. Thus, this post assumes you are familiar with using git and the command line. If not, I recommend Atlassian’s git tutorials to get started :)
Although commits are explored in this post, there is also a focus on the object model that drives git. This is so that your understanding of commits can be put into context of the wider ‘git landscape’.
1. How commits are stored
The short answer is that a commit is a text file stored within the .git/objects directory. Git stores this file with all the information about a commit: who made it, when it was made, how the files/directories looked like and some other metadata.
The long answer involves understanding the things which make up a ‘commit’.
Git’s Object Database
To keep track of your files, git uses an internal database called the object database. This database is in the .git/objects directory and is at the core of what drives git!
What does the database store?
The database stores three types of objects. Technically there are four, but we will ignore tags in this post. Starting from the simplest and moving up to the complex, they are:
- Blob objects (Simplest)
- Tree objects
- Commit objects (Complex)
Commit objects are the most complex because they house blob objects and tree objects inside them. So, to understand commit objects we need to venture to the land of blob objects first. Next, tree objects and then move onto commit objects last.
Blob objects
A blob object represents a single file in the working directory. The acronym stands for ‘Binary Large OBject’ and is the simplest type of object git deals with.
When a single file is added to the object database, git stores the file as a blob in the database.
Let us run a quick example to see this happening in action.
Creating a blob object
Say we are building a repository to store quotes from the 2003 cult-classic movie, The Room. Every file in this repository will contain a Tommy Wiseau quote in it’s own file. Let us create a new directory, initialise an empty git repository inside it and write our first quote.
$ mkdir the-room-quotes && cd $_
$ git init
$ echo Hi doggy! > quote1.txt
Creating a new file like this (in the working directory) does not automatically write it into git’s object database. We can check the object database to see that it is indeed empty:
$ find .git/objects -type f
( should be empty )
Write blob into object database
To write objects into the database, we have to add this file to the staging area using ‘git add’. The staging area is a middle-ground between the working directory and .git directory. If you add a file using git add you would be moving it from the working directory into the staging area.
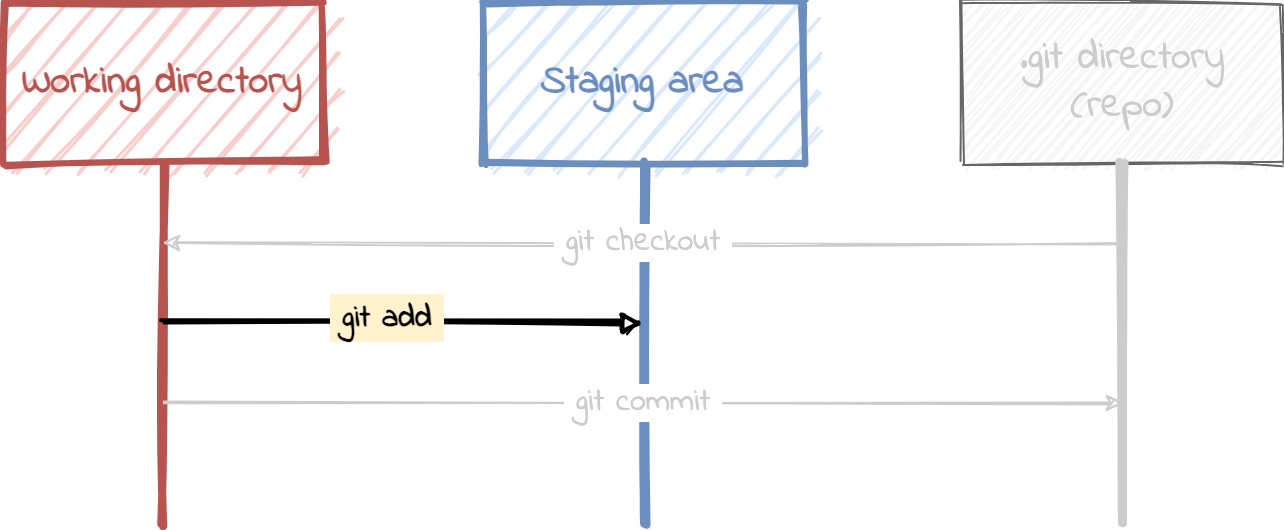
$ git add .
$ find .git/objects -type f
.git/objects/7a/aeff605349ee86ab6ed6f9d70ce5a617b596e9
It seems a new object has appeared in the database. But what’s inside it?
Viewing a blob’s contents
Do not attempt to open this file using commands such as ‘cat’, because it is compressed using zlib. Instead use git cat-file -p <id> if you’d like to take a look inside the file.
If we open up the newly created object, we will see the quote we put into it.
$ git cat-file -p 7aaeff605349ee86ab6ed6f9d70ce5a617b596e9
Hi doggy!
Note: ‘git cat-file’ is an internal helper function. There are other types of these helpers, called ‘plumbing’ commands. For more information about this command take a look the docs.

Adding more files
Currently, only one file is in our working directory.
.
└── quote1.txt
Let us add and stage a few more files and sub-directories. This is so that our database will have some more items inside it. Let us put one more quote in a file in the root directory. Then, we will create a new sub-directory only for quotes directed towards Mark in the movie.
$ echo You are just a chicken, cheep cheep cheep cheep > quote2.txt
$ mkdir to-mark && echo Ha ha ha what a story Mark > to-mark/quote3.txt
$ git add .
Our directory should now look like this:
.
├── quote1.txt
├── quote2.txt
└── to-mark/quote3.txt
If we check the database now, we can see two new objects inside. These two new objects represent the new files we created. These are: (1) quote2.txt, and (2) the sub-directory ‘to-mark’ with the new file quote3.txt inside it.
.git/objects/94/52e922fdbfa6ecabd62fd29fec3e821625c5f6 <---- to-mark/quote3.txt
.git/objects/8a/f3792c43bba0018127f036a6717c508e4b9cea <---- quote2.txt
.git/objects/7a/aeff605349ee86ab6ed6f9d70ce5a617b596e9

Now that we have some extra files and sub-directories, this will help us understand the next git object type: tree objects.
Tree objects
Blobs are cool, but you want to do represent the structure that your repository is storing. There needs to be some way to group a bunch of files together to call it your ‘working directory.’ This is what the second type of object: git trees do.
Git trees are a grouping of files to represent the state of the working directory. Trees store a snapshot of the contents and hierarchy of the working directory.
A common misconception about git is it only stores the changes with every commit made. This is not true. Git stores a snapshot of the entire working directory with every commit made.
Similarity to UNIX tree-like structure
Git borrows from UNIX’s tree-like file system to help record a snapshot of your working directory.
When creating a tree, git starts from the root directory to begin classifying files inside it. Files in the root directory are recorded as blob objects, and sub-directories are recursively recorded as tree objects. What this means is that for all sub-directories, git repeats the same operation until reaching the bottom-most directory of the working directory. After finishing up, the hierarchy of your working directory will end up looking like a ‘tree.’
Creating the tree
We can create a tree to store a snapshot of the our current working directory and it’s hierarchy:
.
├── quote1.txt "Hi doggy!"
├── quote2.txt "You are just a chicken, cheep cheep cheep cheep"
└── to-mark
└── quote3.txt "Ha ha ha what a story Mark"
By using git write-tree command, git will create a tree based on the files currently in the staging area and output the tree’s id. Let us create a tree of our current working directory.
$ git write-tree
d77cacbb84e5369b537cd62d26d533e04798fab1 <--- root tree id
When we check the object database however…
.git/objects/94/52e922fdbfa6ecabd62fd29fec3e821625c5f6
.git/objects/9c/8563e58a379f1f3e5366075401ea9a6f470591 <--- ?
.git/objects/d7/7cacbb84e5369b537cd62d26d533e04798fab1 <--- root tree object
.git/objects/8a/f3792c43bba0018127f036a6717c508e4b9cea
.git/objects/7a/aeff605349ee86ab6ed6f9d70ce5a617b596e9
There seems to be two new objects in the database after running the write-tree command? We know one of them ‘d7/7cacbb84e5369b537cd62d26d533e04798fab1’ is the root tree object. But what is the other object?
The other object, ‘9c/8563e58a379f1f3e5366075401ea9a6f470591’ is in fact the tree created to represent the new sub-directory for quotes directed to Mark named ‘to-mark/’.
This happens because of how the tree is created recursively. Git creates the tree starting from the root directory. When moving down the working directory’s files, any loose file is named a ‘blob’ and any other sub-directory is created into a separate ‘tree’ on it’s own. This process is repeated until reaching the bottom-most directory. Thus, ‘9c/8563e58a379f1f3e5366075401ea9a6f470591’ was created to capture the sub-directory called ‘to-mark’ inside the working directory.
Conceptually, this is how the tree is stored:
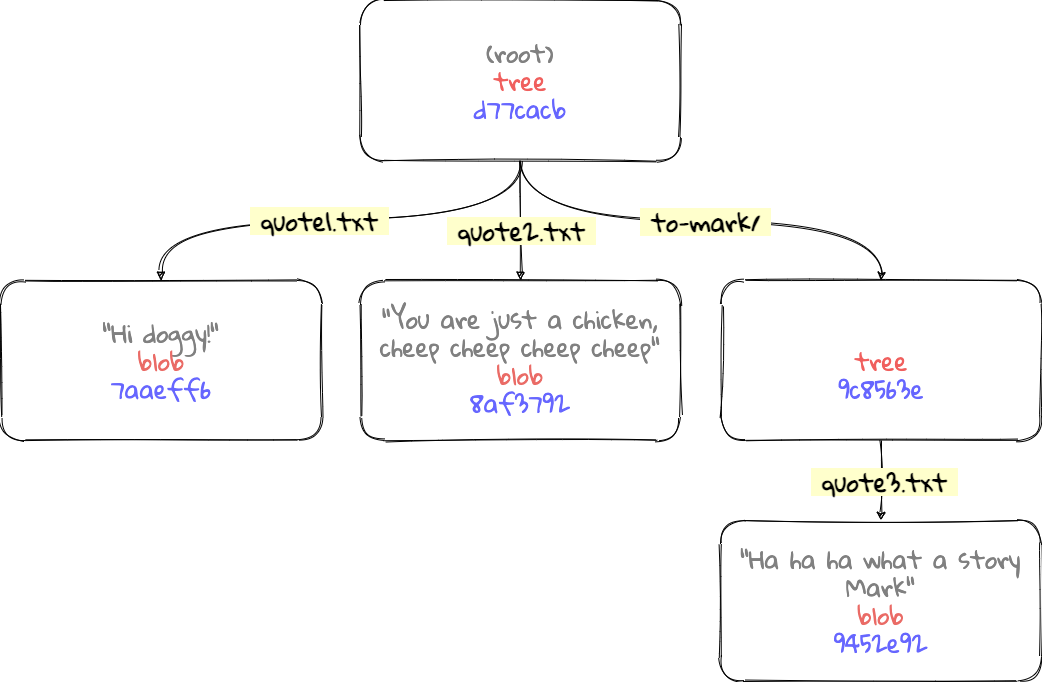
Looking inside the tree objects
If we take a look at the root tree object (‘d77cacb’), we can see three results. Two blobs and one tree:
$ git cat-file -p d77cacb
100644 blob 7aaeff605349ee86ab6ed6f9d70ce5a617b596e9 quote1.txt
100644 blob 8af3792c43bba0018127f036a6717c508e4b9cea quote2.txt
040000 tree 9c8563e58a379f1f3e5366075401ea9a6f470591 to-mark
Note:
d77cacbis the shortened version of the longer hash. You can also use short hashes in place of long hashes as long as you supply enough characters. See the Short SHA-1 section for more information.
Looking at the first row of the command’s output,
- 100644 is from UNIX filesystem mode. This means the object is in normal file mode.
- blob is the type of the object.
- 7aaeff605349ee86ab6ed6f9d70ce5a617b596e9 is the blob object’s id.
- quote1.txt is the file’s name.
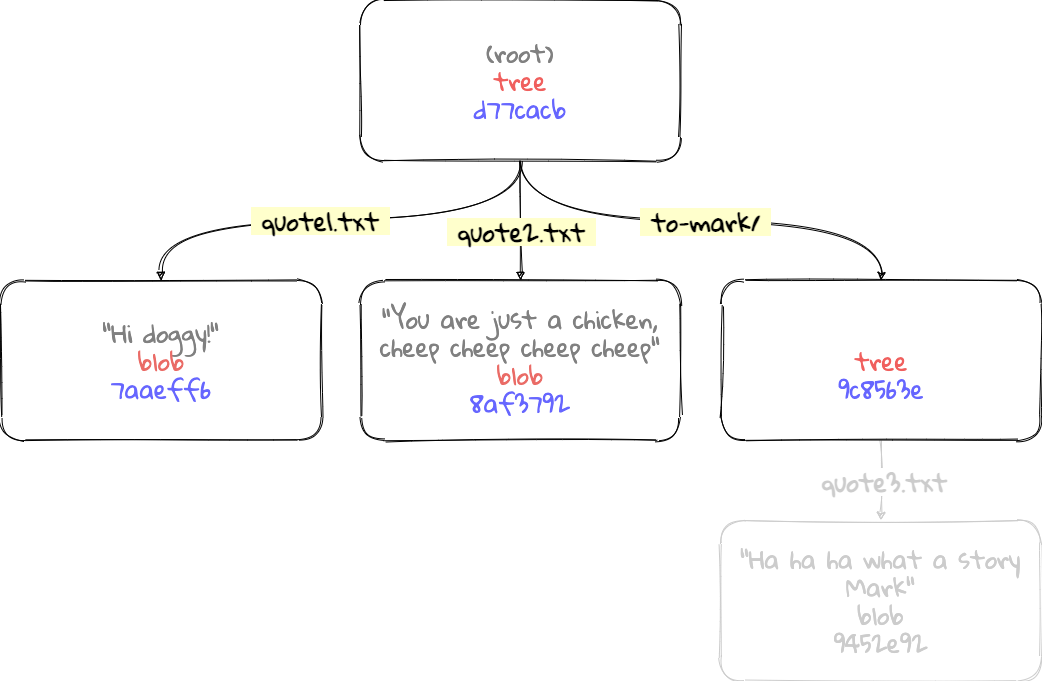
The last line of the command’s output seems points to another tree. This other tree is the sub-directory we created to store Mark’s quotes (‘to-mark’). If we look inside this sub-directory tree (‘9c8563e’), it shows the single ‘quote3.txt’ file.
$ git cat-file -p 9c8563e
100644 blob 9452e922fdbfa6ecabd62fd29fec3e821625c5f6 quote3.txt
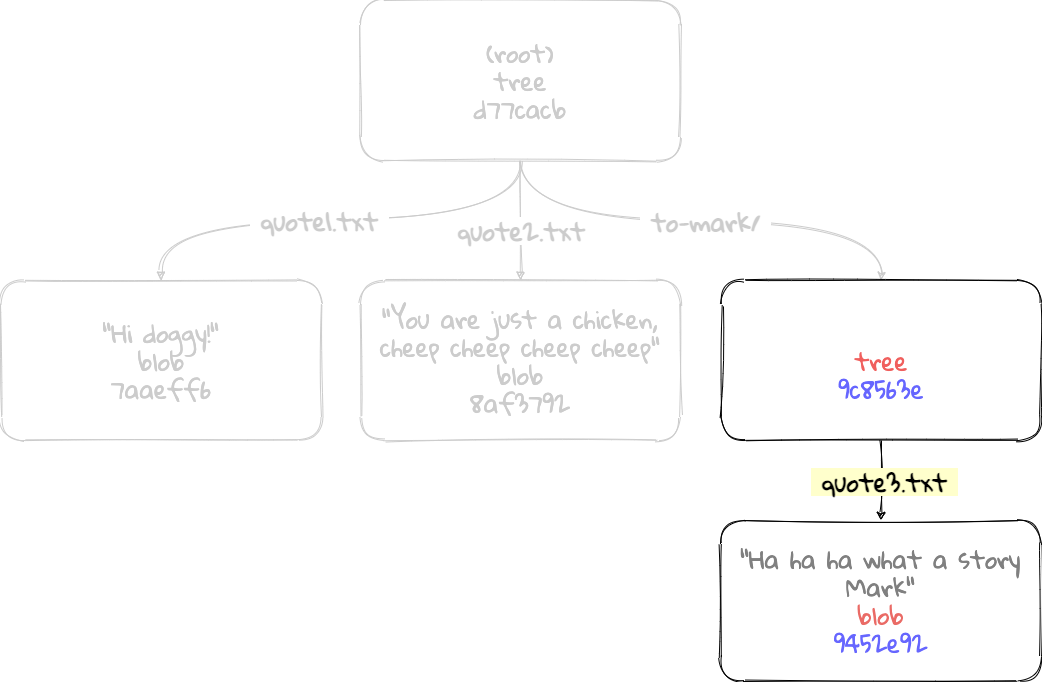
This is what a tree stores: the contents of the working directory along with its hierarchy.
If trees store a snapshot of the working directory, what exactly do commits store?
Commit objects
A git commit is a snapshot of a repository at a point in time. Commits wrap around a tree object with information about when it was created, who created it, why it was created and some other tid-bits.
Since commit objects are a wrapper for tree objects, let us create a commit based off the tree object we created previously (‘d77cacb’).
Create a commit
We can create a commit based on a tree by using the commit-tree command. This command can write a commit message by receiving it via a pipe from stdin.
$ echo 'Wrote three quotes' | git commit-tree d77cacb
5edebefd8e30ffd4bd13ab713689a1b66a62ad7d <-- commit id
Note: If you are following the terminal commands - this commit id will be different for you. This is because the metadata involved in creating the id will be different between your repository and mine. The upcoming section explains why this is the case.
The result is the commit id, which happens to be another object in the database:
.git/objects/94/52e922fdbfa6ecabd62fd29fec3e821625c5f6
.git/objects/9c/8563e58a379f1f3e5366075401ea9a6f470591
.git/objects/d7/7cacbb84e5369b537cd62d26d533e04798fab1
.git/objects/8a/f3792c43bba0018127f036a6717c508e4b9cea
.git/objects/5e/debefd8e30ffd4bd13ab713689a1b66a62ad7d <-- commit object
.git/objects/7a/aeff605349ee86ab6ed6f9d70ce5a617b596e9
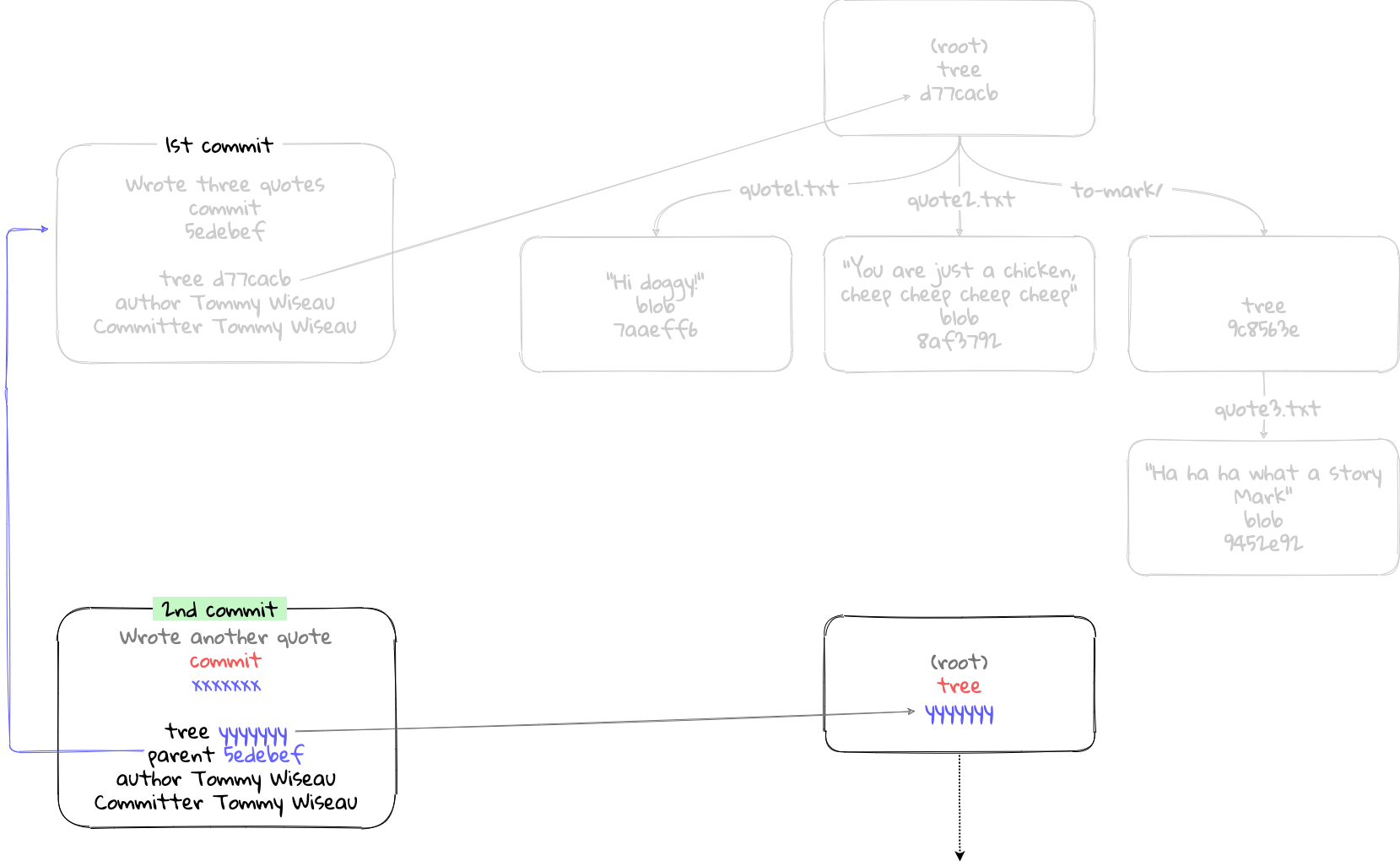
Before we peer into the elusive commit object, let us ensure our current master branch points to this commit object created. This creates the first commit of the master branch we are on. Usually git commit would set this, but this is not the case when using internal plumbing commands.
$ git update-ref refs/heads/master 5edebef
2. What information is inside a commit
The commit object is like any other object in the database: a file. Which means the file can be opened up to see what is inside it. We can look inside the commit object (‘5edebef’) using the git cat-file -p command we have using all along.
$ git cat-file -p 5edebef
tree d77cacbb84e5369b537cd62d26d533e04798fab1
author Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
committer Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
Wrote three quotes
This is the output of the commit object inside the database! In reality, there is a header prepended to this text which we will explore in the next section.
Taking a look at the output, you will notice some familiar friends. Others might be new.
- tree d77cacbb84e5369b537cd62d26d533e04798fab1 points to the root tree object (from which this commit was created from).
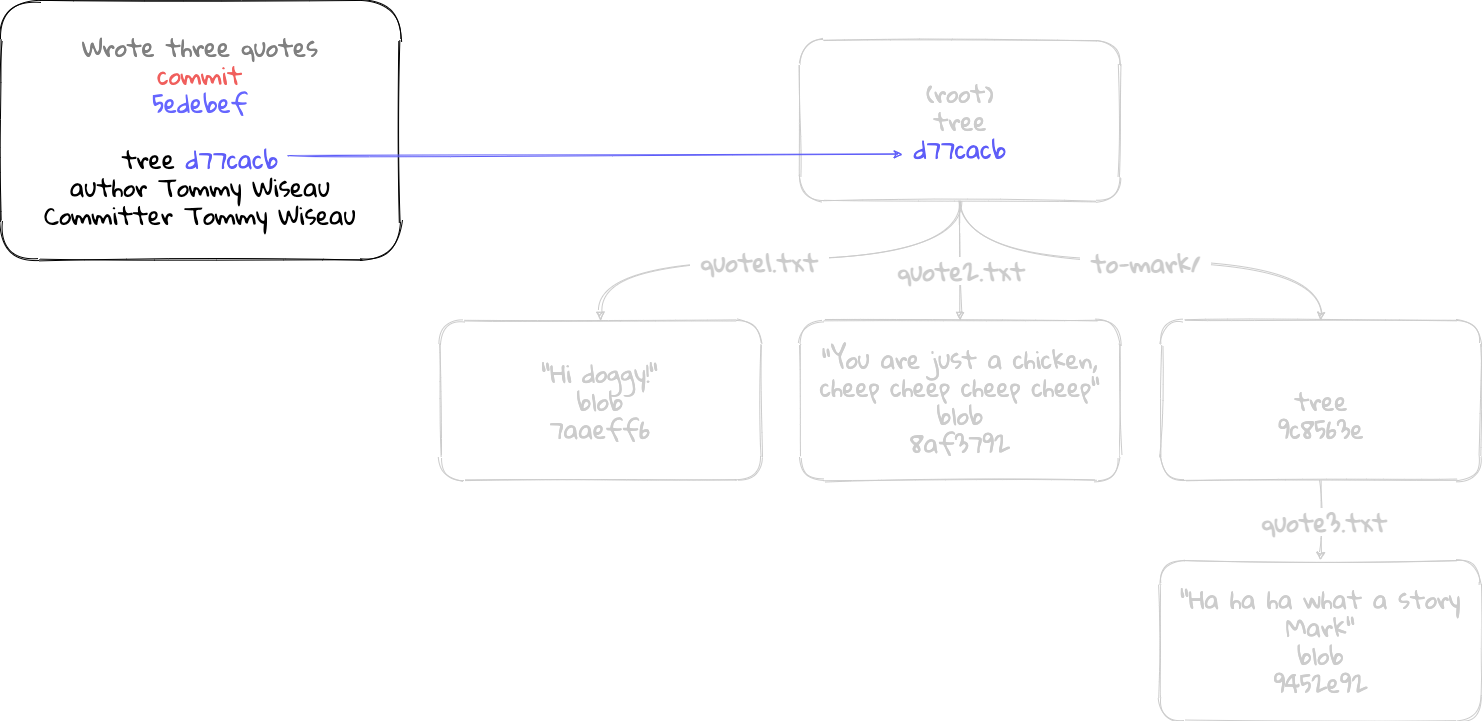
- author is whoever edited the files.
- committer is the person who created the commit.
- ‘Wrote three quotes’ is the commit message written at the time the commit was created.
The reason author and a committer are separate is because these can be two separate people. The distinction is only made clear when running commands which re-write history such as git format-patch or git commit –amend. If history is editable, then both the author of the commit and the committer should be credited for their separate work.
Another entry not visible here, is ‘parent’. Every new commit made sets it’s parent commit as the previous commit made on the current branch. This linking allows every commit to link back to the previous commits made. Following this chain of commits back through time can get you back to the initial commit. The reason it is not visible here is because this is the first commit made to this repository. The first commit does not have a parent commit.
If we created a new commit, the second commit would set the first commit as a parent commit.
Commits signed with a GPG key will also contain a signature below the commit message,
tree d77cacbb84e5369b537cd62d26d533e04798fab1
author Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
committer Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
Wrote three quotes
gpgsig -----BEGIN PGP SIGNATURE-----
hM1/PswpPLuBSr+oCIDj5GMC2r2iEKsfv2fJbNW8iWAXVLoWZRF8B0MfqX/YTMbm
...
8S5B/1SSQuEAjRZgI4IexpZoeKGVDptPHxLLS38fozsyi0QyDyzEgJxcJQVMXxVi
=FSES
-----END PGP SIGNATURE-----
3. How commit ids are generated
When we create a commit, git seems to spit out a series of random letters and numbers for the commit’s id (e.g. ‘5edebef’). What does it mean, and how is it made?

The commit id is a 40 character long string uniquely identifying a commit made to a repository. The id is the result of a SHA-1 hash of a header (the ‘header’) along with the contents of the commit object (the ‘data’).
Introducing SHA-1
SHA-1 is a hash function which works by taking in some input and spitting out a 160-bit (40-characters) hash. It is one-way function, which means it is easy to convert an input into a hash, but difficult to go back.
SHA-1 is part of a family of cryptographic hashing functions which are generally used in cryptography or security settings. However, for git SHA-1 wasn’t chosen by Linus Torvalds for it’s cryptographic properties. It was chosen simply because it was considered a good hash for verifying data integrity.
Since the 2017 SHAttered attack, which found a practical way to generate a SHA-1 collision, future versions of Git (v2.13.0 and up) moved to using a stronger version of the SHA-1 implementation to deal with the collision attack.
How to create a commit id
The commit id is the SHA-1 hash of: (1) a header, (2) a null terminator and (3) a data payload.
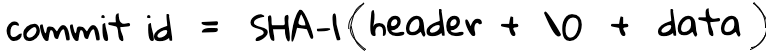
- ‘header’ consists of the word “commit” and the size of the data in bytes.
- ‘data’ is the contents of the git object file exactly how it is shown in the previous section (2. What information is inside a commit). This information in this includes (1) the source tree’s SHA-1, (2) the author, (3) the committer, (3) creation time, (4) a commit message: a message about the purpose of a commit and a (5) parent commit SHA-1, if there is one.
When creating a new commit git calculates the ‘header’ and ‘data’ at that specific point in time, and then runs it through the SHA-1 function to generate the commit id.
Replicating a repository’s latest commit id
To best understand how a commit id is made, let us re-create the latest commit id in a repository.
You can follow along by navigating to any repository that uses git. For this example, I will replicate the latest commit id from the dummy quotes repository, 5edebefd8e30ffd4bd13ab713689a1b66a62ad7d.
Form the header and data
As per the input to the SHA-1 function, we need to form the ‘header’ and the ‘data’. First we will create the ‘data’ variable because the header variable depends on it.
$ data=$(git cat-file commit HEAD)
$ echo $data
tree d77cacbb84e5369b537cd62d26d533e04798fab1
author Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
committer Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
Wrote three quotes
The expression inside the $(), git cat-file commit HEAD returns contents of the latest commit of the current branch.
Next, we will create the ‘header’ variable. This variable will contain the word “commit” as well as the size of the ‘data’ variable created above. The wc -c piped in after the ‘echo $data’ calculates the size of the data in bytes. In this case it is 189 bytes.
$ header=$(printf "commit %s" $(echo $data | wc -c))
$ echo $header
commit 189
Now that both ‘header’ and ‘data’ have been created, let us take a look at how the input to the SHA-1 hash function will look like. The input is the header and the data variables, with a “\0” between them.
$ echo $header"\0"$data
commit 189�tree d77cacbb84e5369b537cd62d26d533e04798fab1
author Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
committer Tommy Wiseau <t.wiseau@theroom.com> 1615298875 +1100
Wrote three quotes
Note: The “\0” is not visible in the shell output.
Hash the input with SHA-1
Finally, we pipe the input into the SHA-1 command. Use sha1sum (or shasum on MacOS).

$ echo $header"\0"$data | sha1sum
5edebefd8e30ffd4bd13ab713689a1b66a62ad7d -
The output will be the commit id of our latest commit. Ta da! This is how git generates this commit id.
In the source code, the write_object_file_prepare function in object-file.c file calculates this hash. You can take a look at the source code here.
It is worth mentioning at this point that in fact the hashes for all git objects are created the same way. Not just commits.
- Blob ids are generated by hashing a header (the size of the blob’s contents) and data (contents of the blob).
- Tree ids are generated by hashing a header (the size of the tree’s contents) and data (contents of the tree).
Why are the object files stored in two character sub-directories?
An observation you may have made is that objects in the database look different to the commit ids/hashes used. The hash is a 40-length string. But, the database object is the first two characters as a sub-directory. Then last hash’s last 38 characters is the file name.
5edebefd8e30ffd4bd13ab713689a1b66a62ad7d <-- commit id
.git/objects/5e/debefd8e30ffd4bd13ab713689a1b66a62ad7d <-- git object file ('loose object')
The structure of the object database looks like the following. Objects stored like this are called ‘loose objects.’
.git/objects
├── 5e
│ └── debefd8e30ffd4bd13ab713689a1b66a62ad7d
├── 7a
│ └── aeff605349ee86ab6ed6f9d70ce5a617b596e9
├── 8a
│ └── f3792c43bba0018127f036a6717c508e4b9cea
├── 94
│ └── 52e922fdbfa6ecabd62fd29fec3e821625c5f6
├── 9c
│ └── 8563e58a379f1f3e5366075401ea9a6f470591
├── d7
│ └── 7cacbb84e5369b537cd62d26d533e04798fab1
├── info
└── pack
There are a few answers for the different formats between the commit id and the database object.
Sub-directory limits: Some older file systems only allow a certain number of files in a directory. For example, ext-2 and ext-3 allow a maximum of ~32k sub-directories within a directory. Reaching this limit can occur quite quickly for large git repositories. The cool thing about SHA-1 is that it distributes hashes well (even across the first two letters) which means it can splay the individual files across the sub-directories without putting too many of the files into the same two-character bucket.
Efficiency: Git relies on the object database to store and retrieve most git objects. Efficient access to these files keeps git fast.
Think about the situation that git does not store files inside 2-character sub-directories. Instead, it would have to place all loose objects into the root .git/objects directory. Every time git wants to find an object using an id, it would need to perform a linear scan of the entire directory. Adding a layer of separation limits the initial search space to a maximum of 256 (2^16) sub-directories only.
One other point is that what we have done so far is only relevant for simple git directories which store loose objects. Once git has more than 6700 (a magic number) loose objects in the database. If this limit is exceeded, git will begin to automatically ‘pack’ files into anothter type of efficient data structure for better file access. However that is for another post.
Here are some resources if you would like to learn more about commits!
- Git internals - Objects: https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
- Git garbage collection and packing: https://git-scm.com/docs/git-gc
- Plumbing and Porcelain commands: https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain
- Replicating the SHA-1 commit id: https://gist.github.com/masak/2415865
- Short ids: https://git-scm.com/book/en/v2/Git-Tools-Revision-Selection
Thanks for reading!